Zechen Bai 白泽琛Ph.D. Candidate
Show Lab, National University of Singapore |
 |
Biography
I'm a PhD candidate at Show Lab, National University of Singapore, advised by Prof. Mike Shou.
I was a Research Scientist Intern at Meta Superintelligence Lab (MSL), building Muse Spark 🥑 and Segment Anything. Previously, I spent wonderful time at AWS AI Lab, ByteDance Intelligent Creation Lab, and Baidu VIS.
I mainly work on video understanding and multimodal learning. I'm particularly interested in structural perception, grounding, and their applications in reasoning and interaction.
- Object-centric Perception: specialize in unsupervised object discovery (Video Slot Attention ICCV'23, CVPR'24) to tackle the binding problem, building models that decompose dynamic scenes into visual entities.
- Grounded Visual Reasoning: bridge the gap between high-level reasoning and fine-grained entities by developing reasoning-centric perception models (VideoLISA NeurIPS'24) and benchmarks (Impossible Videos ICML'25).
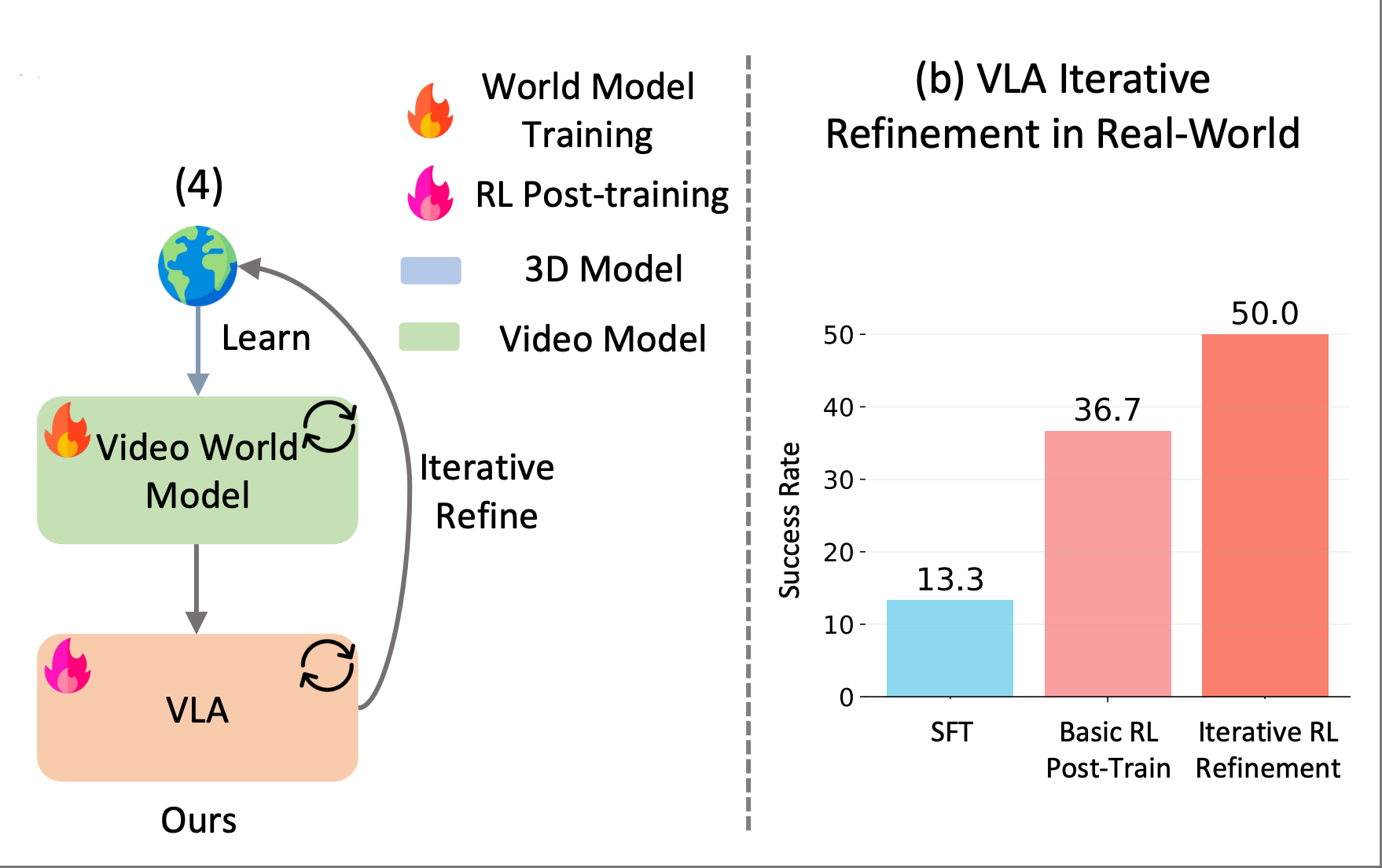
- Structural Visual Interaction: explore how structural perception can elicit complex behaviors and activate executable knowledge in both digital (Demo2Tutorial CVPR'26) and physical environments (World-VLA-Loop).
I also enjoyed the research experience on virtual reality and human-computer interaction in my early years.
Open to full-time and internship opportunities. Please drop me an email if interested.
News
- [04/2026] We launched Muse Spark 🥑!
- [02/2026] Two papers accepted by CVPR 2026! Congrats and thanks to all the co-authors!
- [11/2025] I stared internship at Meta Superintelligence Lab, with the amazing Segment Anything team!
- [09/2025] Two papers accepted by NeurIPS 2025! Congrats and thanks to all the co-authors!
- [05/2025] Impossible Videos is accepted by ICML 2025!
- [03/2025] We released Impossible Videos, a novel & challenging benchmark for both video understanding and generation models!
- [02/2025] Invited talk on VideoLISA hosted by Twelve Labs. Check out the YouTube video!
- [02/2025] ShowUI is accepted by CVPR 2025! Congrats to Kevin!
- [01/2025] Two papers accepted by ICLR 2025! Congrats to the team!
- [09/2024] We have three papers accepted by NeurIPS 2024! Check out VideoLISA, LOVA3, and DoFIT!
- [08/2024] We released Show-o, a single transformer model that unifies multimodal understanding and generation!
- [04/2024] We released a comprehensive survey of hallucination in multimodal large language models, check out the paper!
- [03/2024] One paper accepted by ICLR 2024 Reliable and Responsible Foundation Models Workshop!
- [02/2024] Two papers accepted by CVPR 2024! Congrats to co-authors!
- [01/2024] A long paper accepted by IEEE-VR 2024!
- [09/2023] After a wonderful year at Amazon, I enrolled in NUS as a PhD student!
- [07/2023] Two papers were accepted to ICCV 2023!
- [01/2023] One paper was accepted to IEEE-VR 2023.
- [11/2021] I was awarded China National Scholarship.
- [07/2021] One paper was accepted to ICCV 2021.
- [05/2021] One paper was accepted to CASA 2021, and then selected to appear in the Journal of CAVW.
- [04/2021] My first-author work has won the Best Poster Award in IEEE-VR 2021!
- [03/2021] One paper was accepted to CVPR 2021 as Oral presentation!
- [02/2021] One poster was accepted to IEEE-VR 2021.
- [04/2020] We have won the Champion in AICity Challenge Vehicle Re-id Track in CVPR 2020!
- [12/2019] One paper was accepted to AAAI 2020.
Selected Publications (*co-first author)

|
Muse Spark: Scaling Towards Personal Superintelligence. MSL Team. 2026. |

|
Demo2Tutorial: From Human Experience to Multimodal Software Tutorials. Zechen Bai, Zhiheng Chen, Yiqi Lin, Kevin Qinghong Lin, Difei Gao, Xiangwu Guo, Xin Wang, Mike Zheng Shou CVPR, 2026. |
|
World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy. Xiaokang Liu*, Zechen Bai*, Hai Ci, Kevin Yuchen Ma, Mike Zheng Shou arXiv preprint, 2026. [Paper] [ProjectPage] |
|
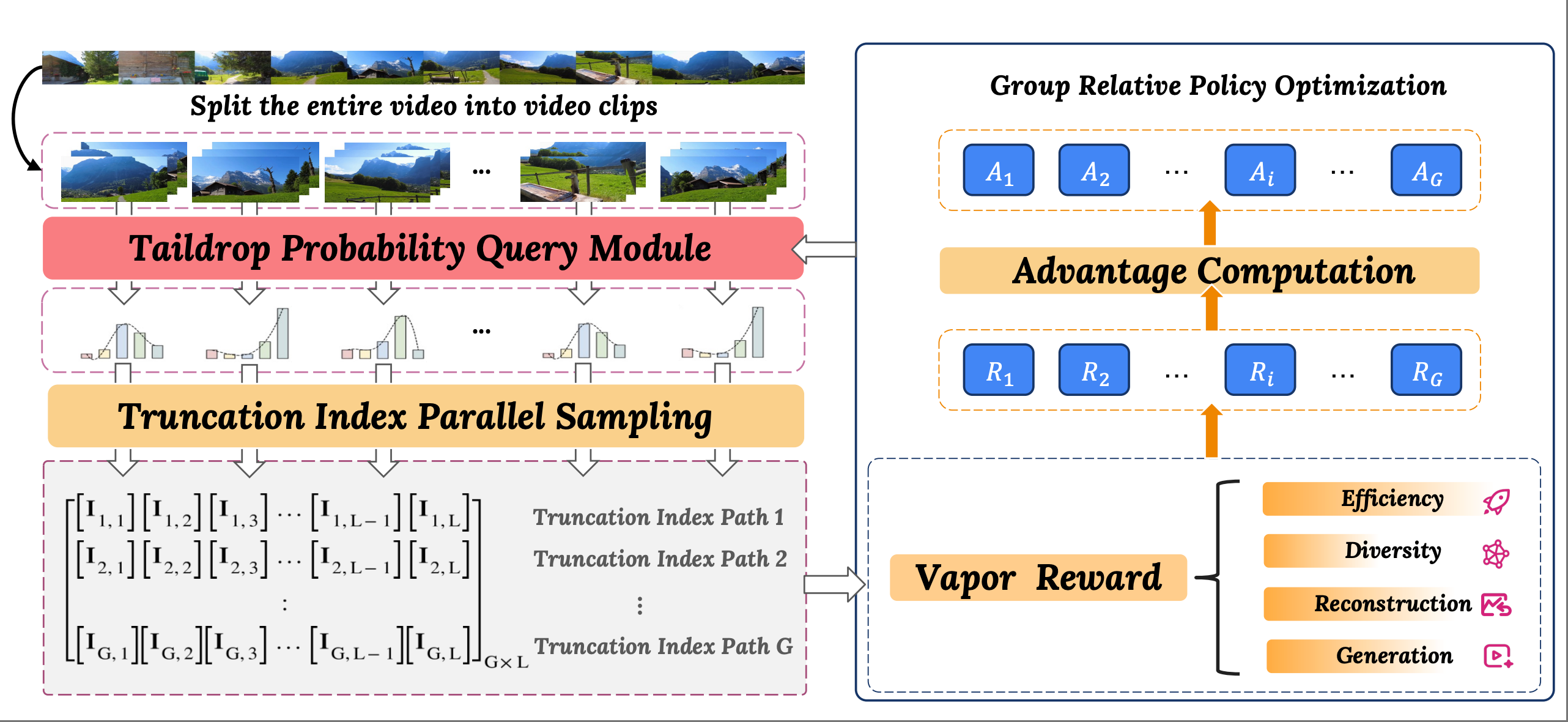
VaporTok: RL-Driven Adaptive Video Tokenizer with Prior and Task Awareness. Minghao Yang*, Zechen Bai*, Jing Lin, Haoqian Wang, Alex Jinpeng Wang NeurIPS, 2025. [Paper] |
|
|
Impossible Videos. Zechen Bai*, Hai Ci*, Mike Zheng Shou ICML, 2025. [Paper] [Homepage] [GitHub] [HuggingFace] |
|
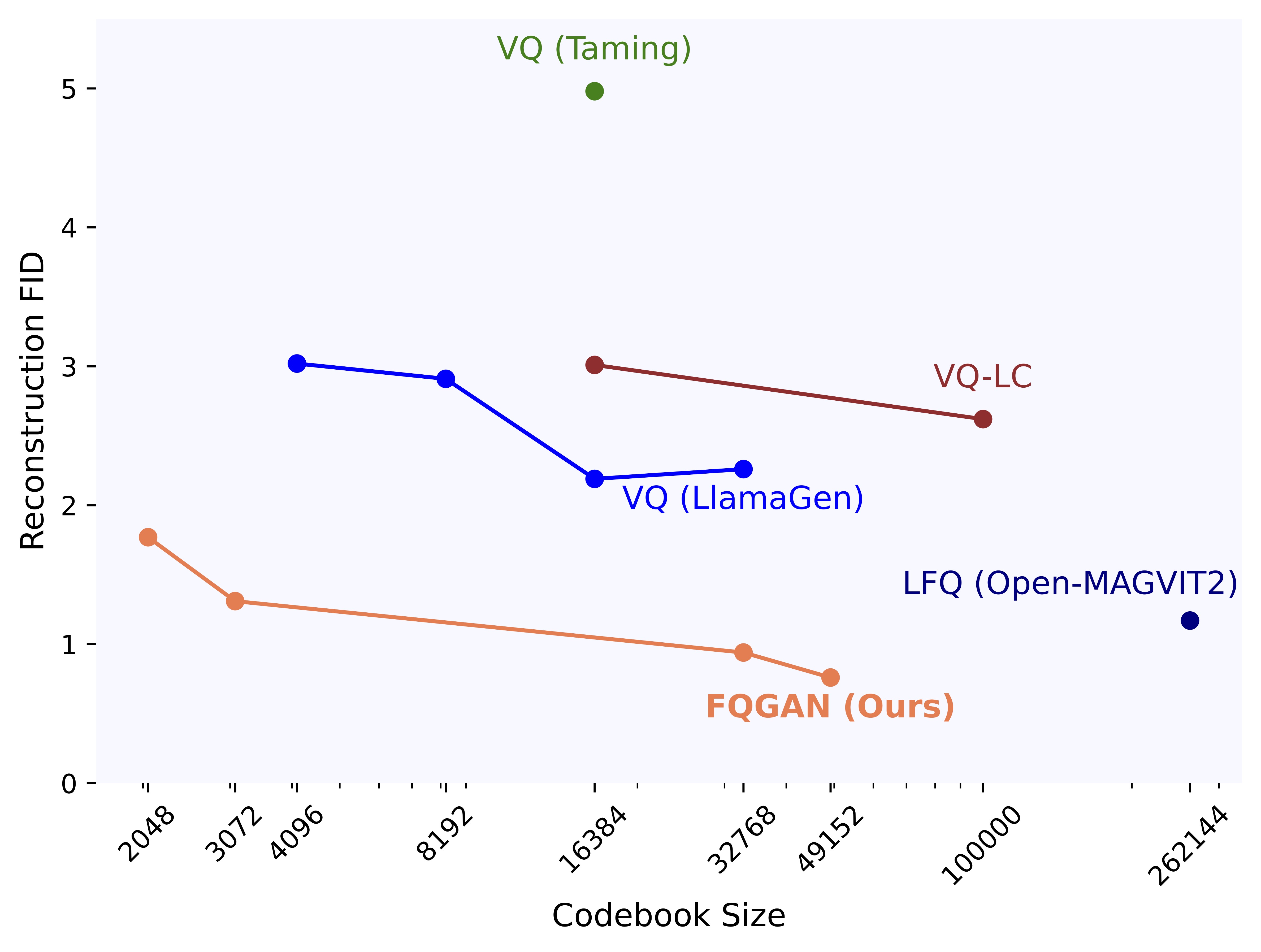
Factorized Visual Tokenization and Generation. Zechen Bai, Jianxiong Gao, Ziteng Gao, Pichao Wang, Zheng Zhang, Tong He, Mike Zheng Shou arXiv preprint, 2024. |

|
Bridging Information Asymmetry in Text-video Retrieval: A Data-centric Approach. Zechen Bai, Tianjun Xiao, Tong He, Pichao Wang, Zheng Zhang, Thomas Brox, Mike Zheng Shou ICLR, 2025. [Paper] |
|
|
Show-o: One Single Transformer To Unify Multimodal Understanding and Generation. Jinheng Xie*, Weijia Mao*, Zechen Bai*, David Junhao Zhang*, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, Mike Zheng Shou ICLR, 2025. [Paper] [ProjectPage] [Code] |

|
One Token to Seg Them All: Language Instructed Reasoning Segmentation in Videos. Zechen Bai, Tong He, Haiyang Mei, Pichao Wang, Ziteng Gao, Joya Chen, Lei Liu, Zheng Zhang, Mike Zheng Shou NeurIPS, 2024. |
|
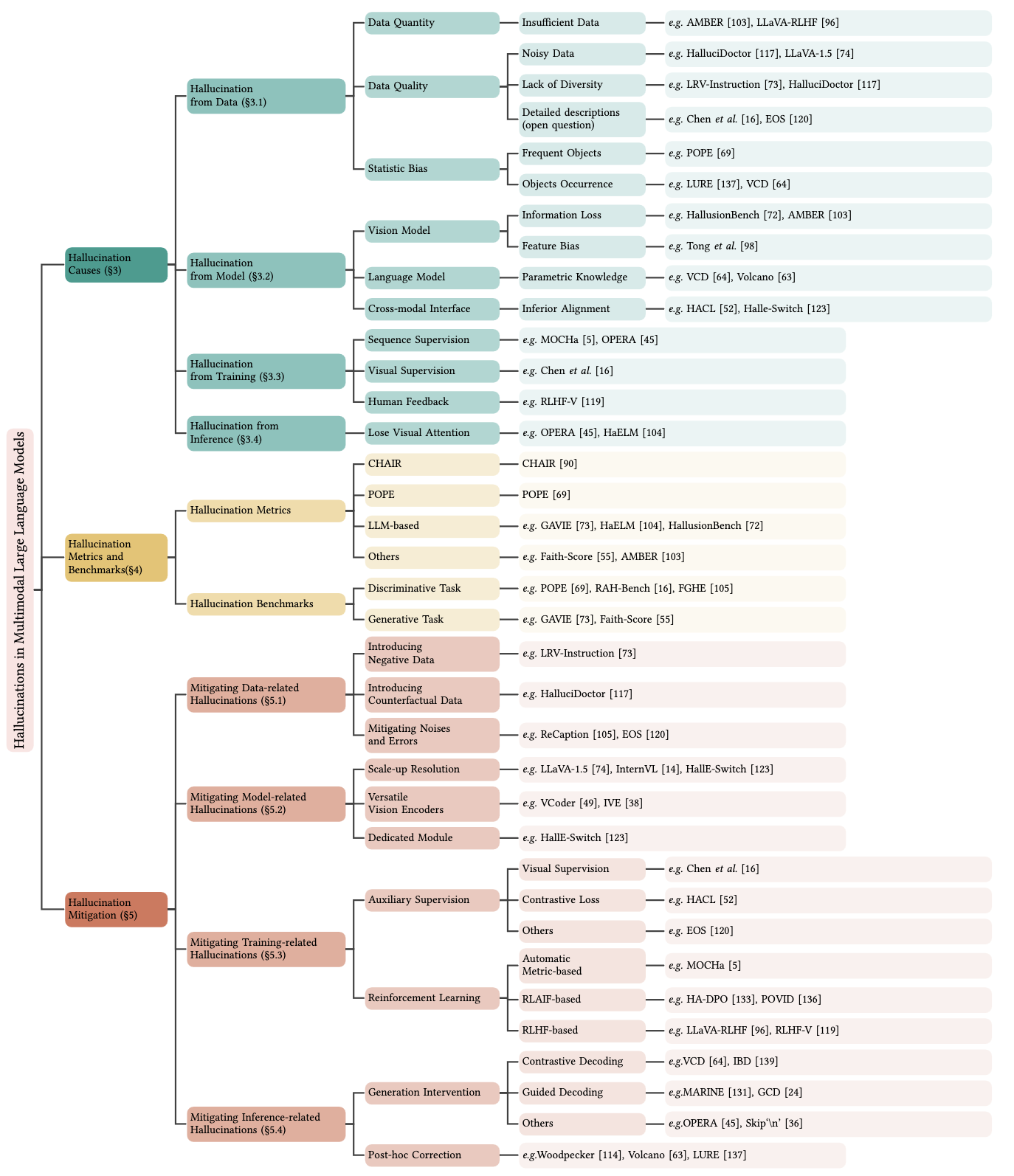
Hallucination of Multimodal Large Language Models: A Survey. Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou arXiv preprint, 2024. [Paper] [ProjectPage] |
|
|
Skip \n: A Simple Method to Reduce Hallucination in Large Vision-Language Models. Zongbo Han, Zechen Bai, Haiyang Mei, Qianli Xu, Changqing Zhang, Mike Zheng Shou ICLR R2-FM Workshop, 2024. [Paper] |
|
|
AssistGUI: Task-Oriented Desktop Graphical User Interface Automation. Difei Gao, Lei Ji, Zechen Bai, Mingyu Ouyang, Peiran Li, Dongxing Mao, Qinchen Wu, Weichen Zhang, Peiyi Wang, Xiangwu Guo, Hengxu Wang, Luowei Zhou, Mike Zheng Shou CVPR 2024. [Paper] [Code] [ProjectPage] |

|
Adaptive Slot Attention: Object Discovery with Dynamic Slot Number. Ke Fan, Zechen Bai, Tianjun Xiao, Tong He, Max Horn, Yanwei Fu, Francesco Locatello, Zheng Zhang. CVPR 2024. |

|
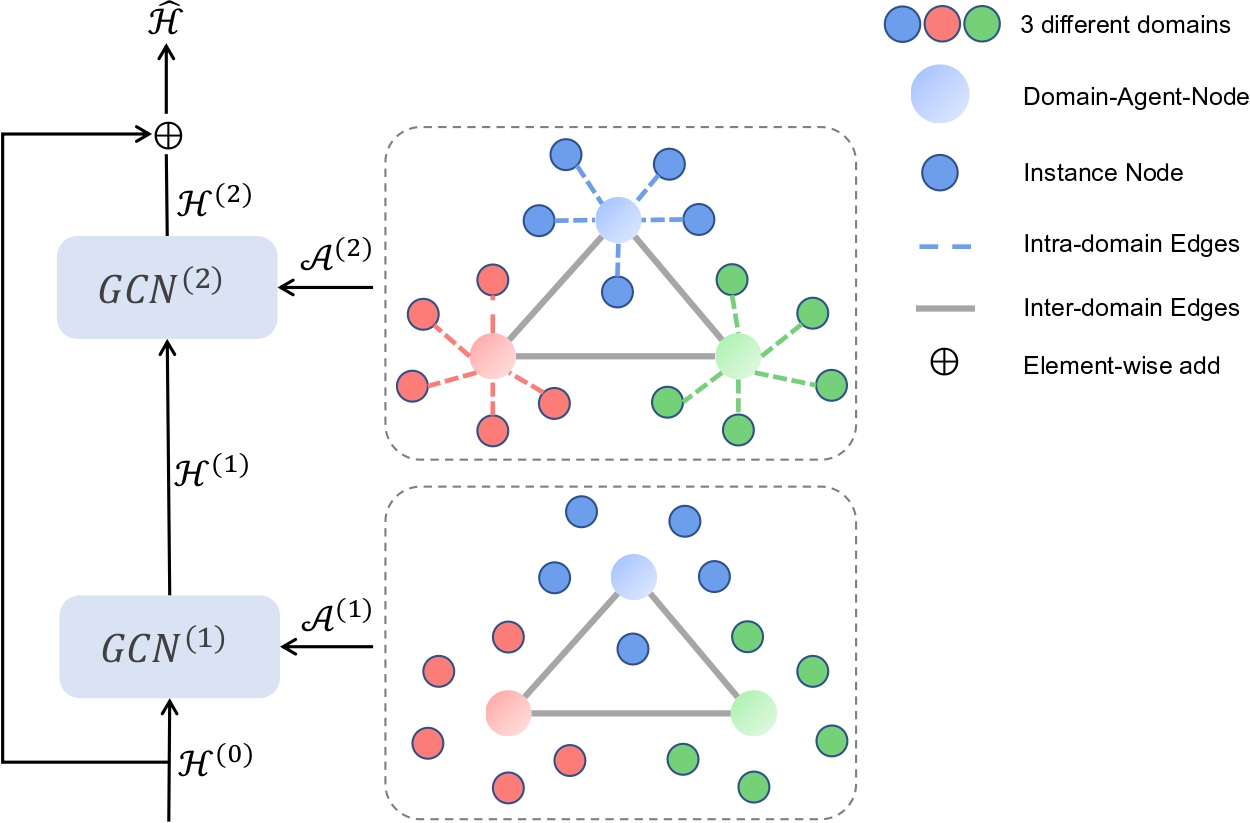
Unsupervised Open-Vocabulary Object Localization in Videos. Ke Fan*, Zechen Bai*, Tianjun Xiao, Dominik Zietlow, Max Horn, Zixu Zhao, Carl-Johann Simon-Gabriel, Mike Zheng Shou, Francesco Locatello, Bernt Schiele, Thomas Brox, Zheng Zhang, Yanwei Fu, Tong He ICCV 2023. * Equal contribution. Ke is the first intern author, Zechen is the first FTE author. |
|
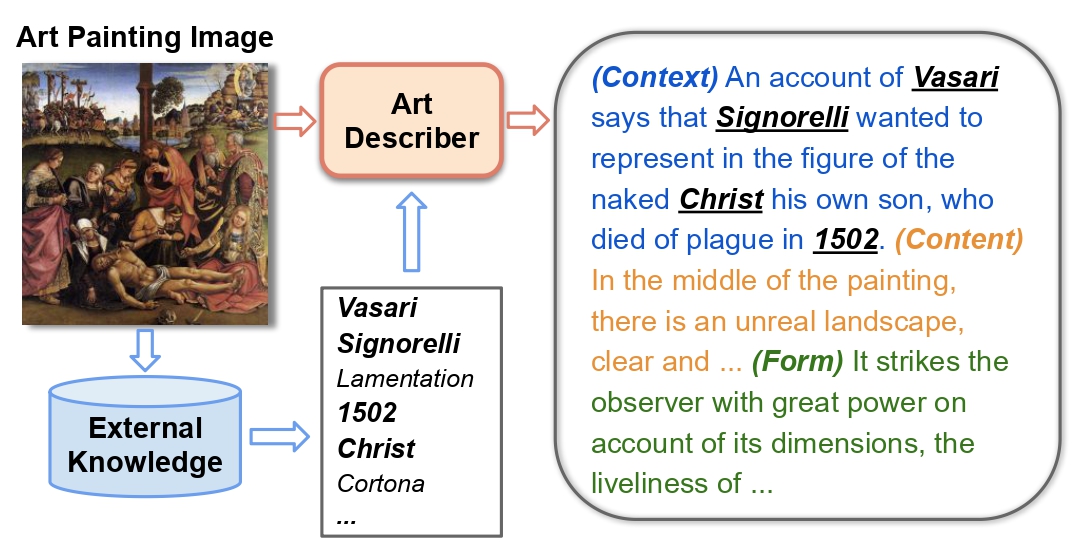
Explain Me the Painting: Multi-Topic Knowledgeable Art Description Generation. Zechen Bai, Yuta Nakashima, and Noa Garcia. ICCV 2021. [Paper][Code][ProjectPage] |
|
Unsupervised Multi-Source Domain Adaptation for Person Re-Identification. Zechen Bai, Zhigang Wang, Jian Wang, Di Hu, Errui Ding. CVPR 2021. (Oral) |

|
Show, Recall, and Tell: Image Captioning with Recall Mechanism. Li Wang*, Zechen Bai*, Yonghua Zhang, Hongtao Lu. AAAI 2020. [Paper] |
Virtual Reality
|
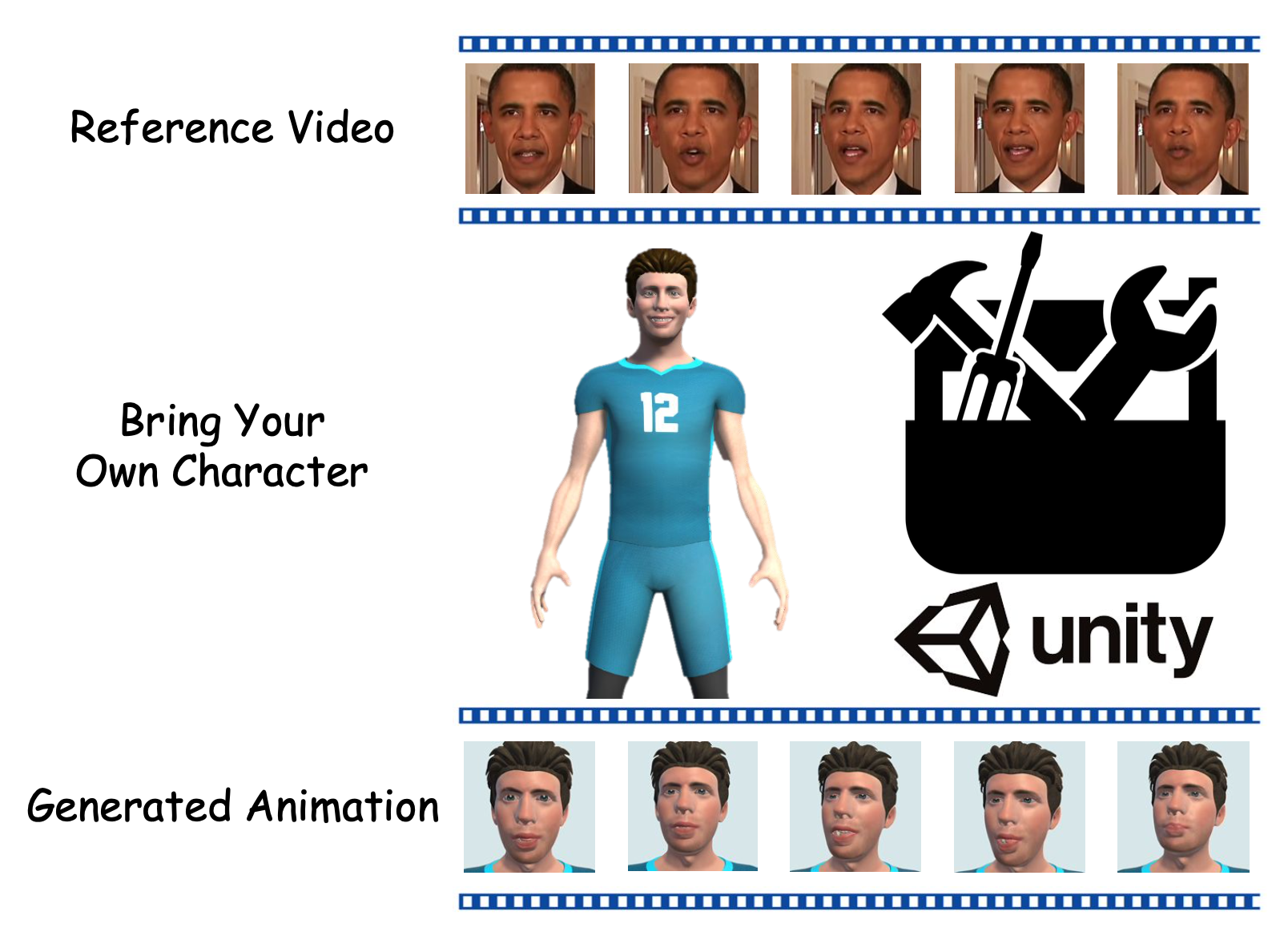
Bring Your Own Character: A Holistic Solution for Automatic Facial Animation Generation of Customized Characters. Zechen Bai, Peng Chen, Xiaolan Peng, Lu Liu, Hui Chen, Mike Zheng Shou, Feng Tian. IEEE Virtual Reality Conference (VR), 2024. |
|
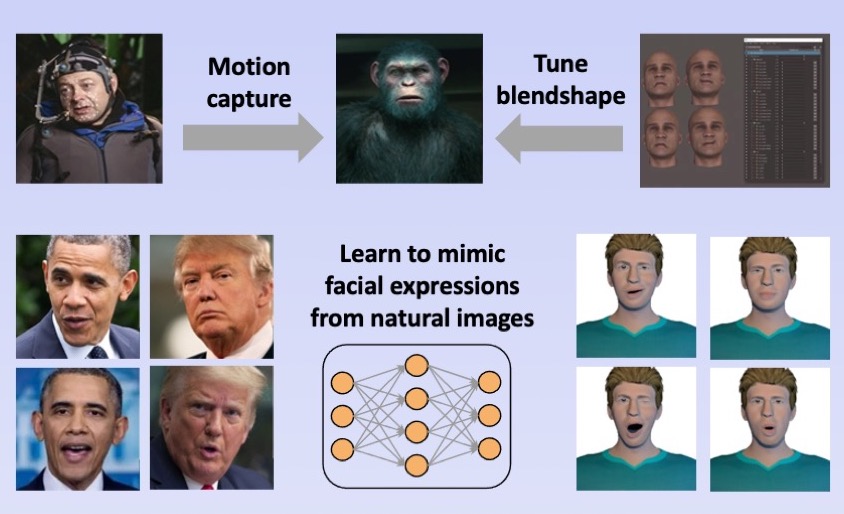
A Simple Approach to Animating Virtual Characters by Facial Expressions Reenactment. Zechen Bai, Naiming Yao, Lu Liu, Hui Chen, Hongan Wang. IEEE Virtual Reality Conference (VR), 2023. [Paper] |
|
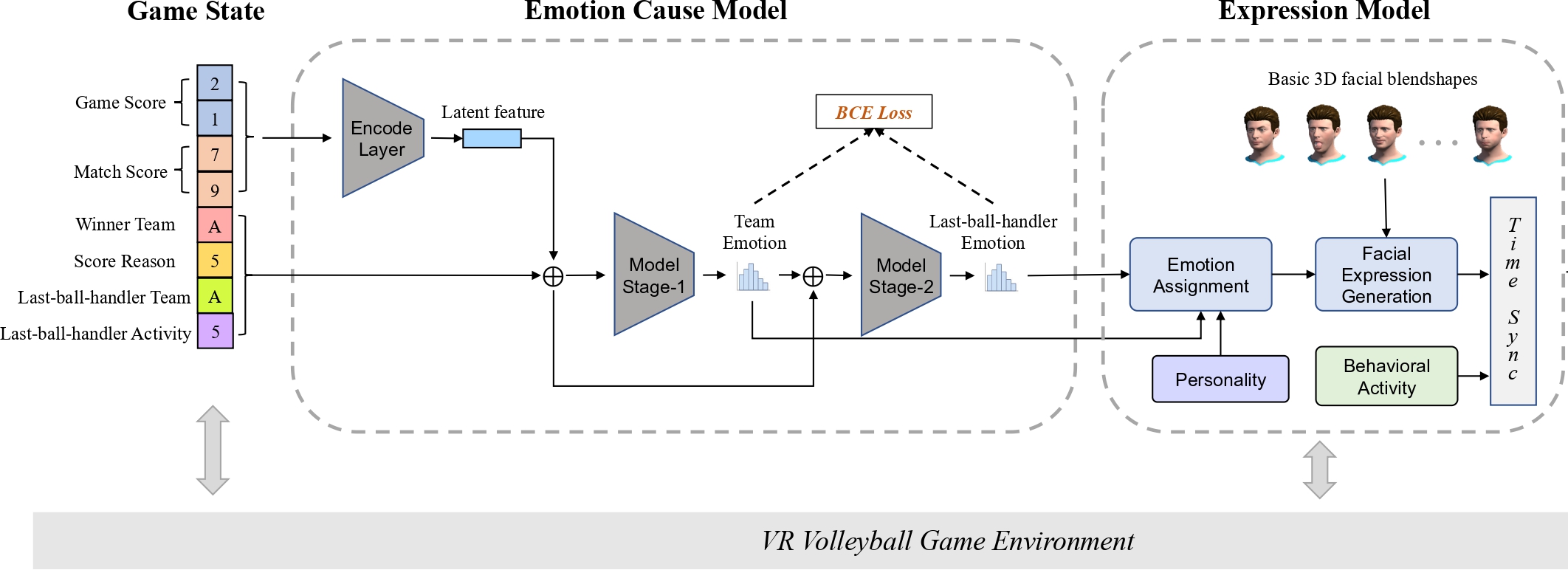
Enhancing Emotional Experience by Building Emotional Virtual Characters in VR Volleyball Games. Zechen Bai, Naiming Yao, Nidhi Mishra, Hui Chen, Hongan Wang, Nadia Magnenat Thalmann. International Conference on Computer Animation and Social Agents (CASA), 2021. [Paper] |

|
Play with Emotional Characters: Improving User Emotional Experience by A Data-driven Approach in VR Volleyball Games. Zechen Bai, Naiming Yao, Nidhi Mishra, Hui Chen, Hongan Wang, Nadia Magnenat Thalmann. IEEE Virtual Reality Conference (VR), 2021. (Best Poster Award!) [Paper] |
Academic Service
I serve as reviewers for conferences including CVPR, ICCV, ECCV, NeurlPS, ICLR, ICML, ACM MM, etc and journals/transactions including TIP, TCSVT, Neurocomputing, ACM Computing Survey, etc.Selected Awards
| PREMIA Best Student Paper Award (Excellence), 2025 |
| NeurIPS Scholar Award, 2024 |
| China National Scholarship, 2021 |
| Best Poster Award at IEEE-VR 2021 |
| Beijing Distinguished Graduate Award, 2019 |
© Zechen Bai | Last updated: May 2026